Performing a date randomisation test
About the date randomisation feature
Caution
The date randomisation feature is intended as an exploratory test for root-to-tip temporal signal. It is not a substitute for full molecular clock model comparison or formal phylodynamic inference.
Date randomisation is a permutation test for temporal signal. It asks whether the observed relationship between sampling time and genetic divergence is stronger than would be expected if sampling dates were unrelated to the sequences.
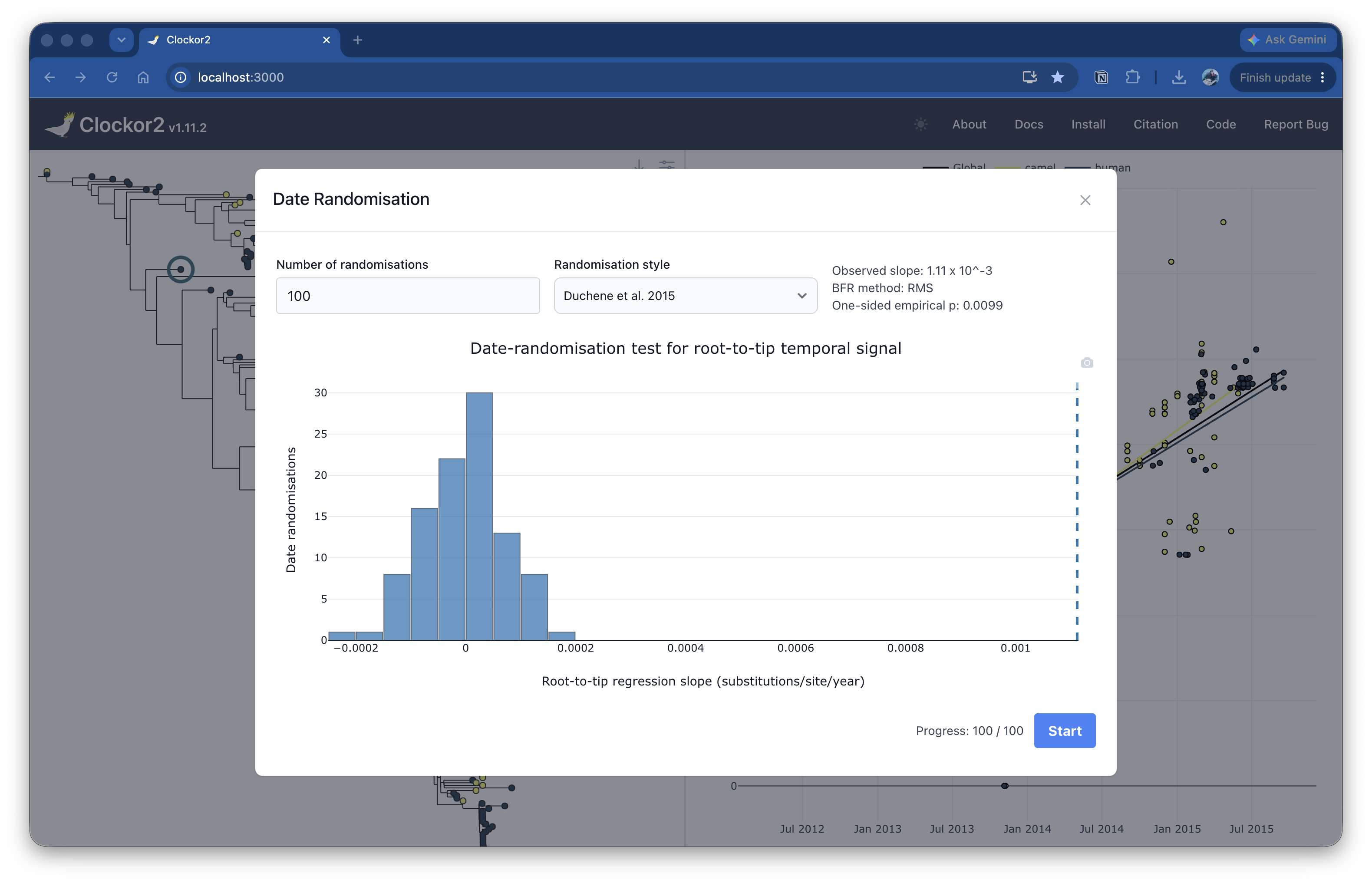
The date randomisation test compares the observed root-to-tip regression slope against slopes obtained after permuting dates across tips. For each randomisation replicate, Clockor2 permutes (sampling without replacement) the sampling dates, finds the best fitting root using the selected BFR settings, recalculates the root-to-tip regression, and adds the resulting slope to the histogram.
The dashed vertical line shows the observed slope from the empirical data. The histogram shows the distribution of slopes from the randomised date replicates. If the observed slope lies far from the centre of this distribution, the empirical sampling times contain more temporal signal than expected under randomised sampling dates.
Clockor2 provides two randomisation schemes:
- Duchene et al. 2015: randomises clusters of tips with the exact same date. This is the default and preserves same-date sampling groups.
- Firth et al. 2010: randomises dates across individual tips.
The empirical p-value is calculated as:
(tail_count + 1) / (number_of_randomisations + 1)
where tail_count is the number of randomised slopes with an absolute value at least as large as the absolute value of the observed slope:
abs(randomised_slope) >= abs(observed_slope)
Using the absolute slope measures the strength of the temporal signal regardless of whether the current plot uses forward sampling dates or tip-height style axes, where the expected clock slope may have the opposite sign.
Larger numbers of randomisations give a smoother null distribution and a more precise empirical p-value, but take longer to compute. Date randomisation can be slow for large trees because each replicate performs a best fitting root search.